イントロ
こんにちは、ニートです。
この夏もまた、glibc の新しいバージョン(2.32)のリリース日が近づいてきました。 今回のアップデートでは、malloc/free にSafe Linkingというものが追加されます(多分。知らんけど)。 かつて 2005 年の glibc2.3.6 において実装されたSafe-Unlinkingを彷彿とさせる忌々しい名前ですね。 本エントリでは、この Safe Linking を概観してみようと思います。 それと同時に、Safe-Linking の bypass 方法についても概観し、ほんの少しだけ触れてみようと思います。
尚、この先触れる内容は実は前々から実装されていたかもしれませんが、 自分が気づいた時其れ即ち実装された時ということで、悪しからず。
Safe-Linking 概観
Safe-Linkingは、2020 年 8 月 1 日リリースの Glibc 2.32 においてリリースが予定され
既にmasterブランチに乗っている、heap exploitation に対する mitigation のことである。
設計者によると、以下の 3 つの攻撃に対して防衛的役割を果たすとされている:
Our solution protects against 3 common attacks regularly used in modern day exploits: Partial pointer override: Modifying the lower bytes of the pointer (Little Endian). Full pointer override: Hijacking the pointer to a chosen arbitrary location. Unaligned chunks: Pointing the list to an unaligned address.
まずは、実際に Safe-Linking が実装されている glibc でバイナリを動かしたときの heap の様子を見てみることにする。 以下のソースコードを glibc 2.32 用にビルドした:
example.c 1#include<stdio.h>
2#include<stdlib.h>
3#include<string.h>
4int main(void)
5{
6 char *a = malloc(0x20);
7 char *b = malloc(0x20);
8 char *c = malloc(0x20);
9 char *d = malloc(0x20);
10 free(a);
11 free(b);
12 free(c);
13 return 0;
14}これを free の直前まで動かした後の heap が以下のようになる:
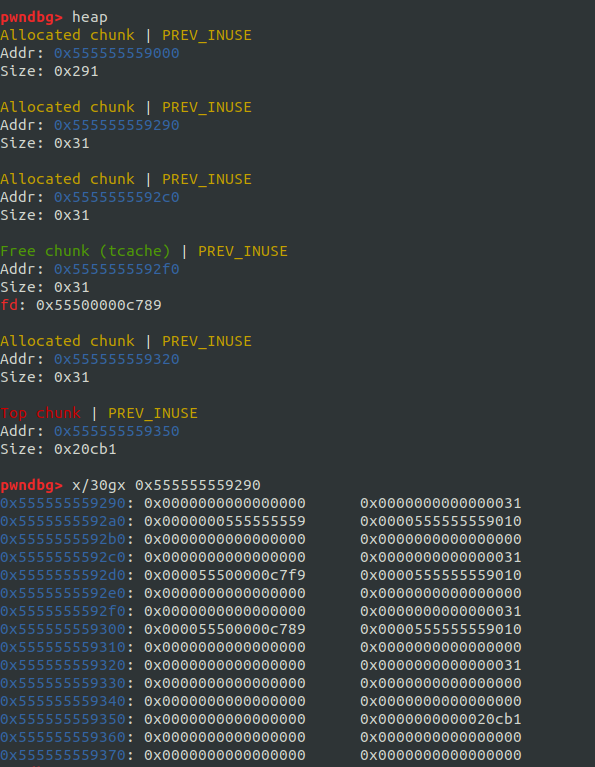
chunk A,B,C の順にmalloc()されており、A,B,C のbkはkey ( > libc 2.29) であるから&tcacheが入っているのは言するに値しないだろう:
それはいいとして、注目すべきは ABC のfdである。
heap addr のように見えるけど、なんかよくわからん値が入っていることが見て取れる。
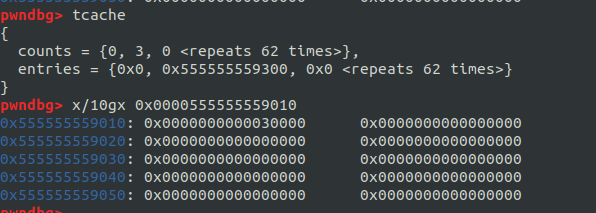
これのおかげで、GDB のbinコマンドによって tcache のリストを見ようとすると以下のようになる:
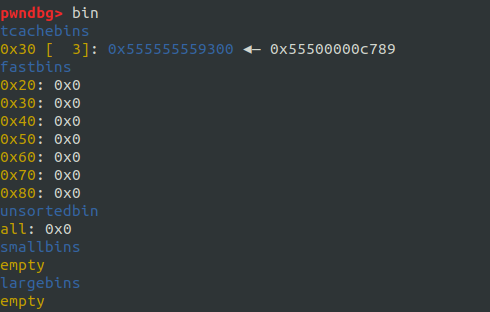
pwndbgが 2.32 に対応していないため、linked list が崩壊していることが分かる。
また、C のfdの LSB を0x00に書き換えて tcache dup を行おうとすると以下のようになる:
1pwndbg> set {char}0x555555559300 = 0x00
2pwndbg> c

malloc(): unaligned tcache chunk detectedというエラーが出て abort していることが分かる。
これにより、少なくとも従来の UAF による LSB 書き換えでの tcache dup は Safe-Linking によって失敗するということがわかるであろう(後述するが、厳密には「失敗する」よりも「失敗する確率が上がる」の方が正しい)。 以下で、その実装を見ていくことにする。
Safe-Linking の実装とその仕組み
実装
まずはtcache_put()の実装を以下に示す:
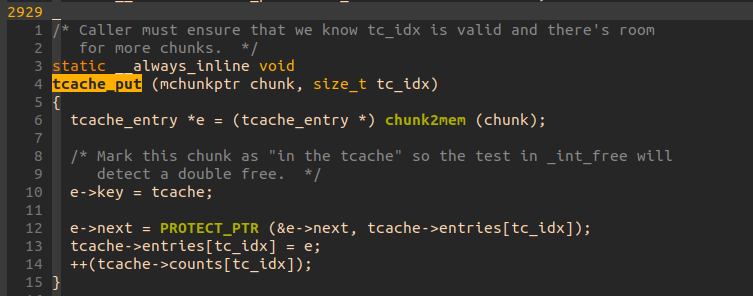
+12 行目においてPROTECT_PTRというマクロに free された chunk のアドレスと tcache に繋がっている最初の bin のアドレスが渡され、その結果がnextに入っていることが分かる。
PROTECT_PTRは以下のように定義される:
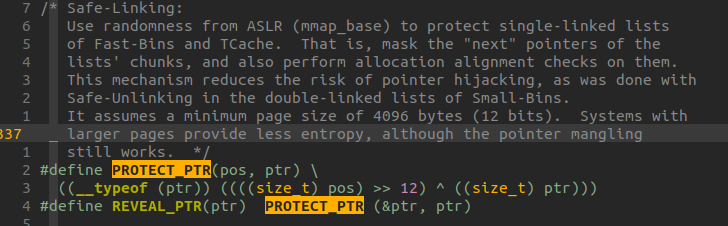
見ての通り、free した chunk のアドレスを 12bit 右シフトした値と従来のnextに入るアドレスの xorを返している。
REVEAL_PTRマクロは後ほど出てくるが、xor をするという性質上PROTECT_PTRを使いまわしている。
深い話は後にして、_int_malloc() / _int_free()を眺める
以下に_int_free()の実装の一部を示す:
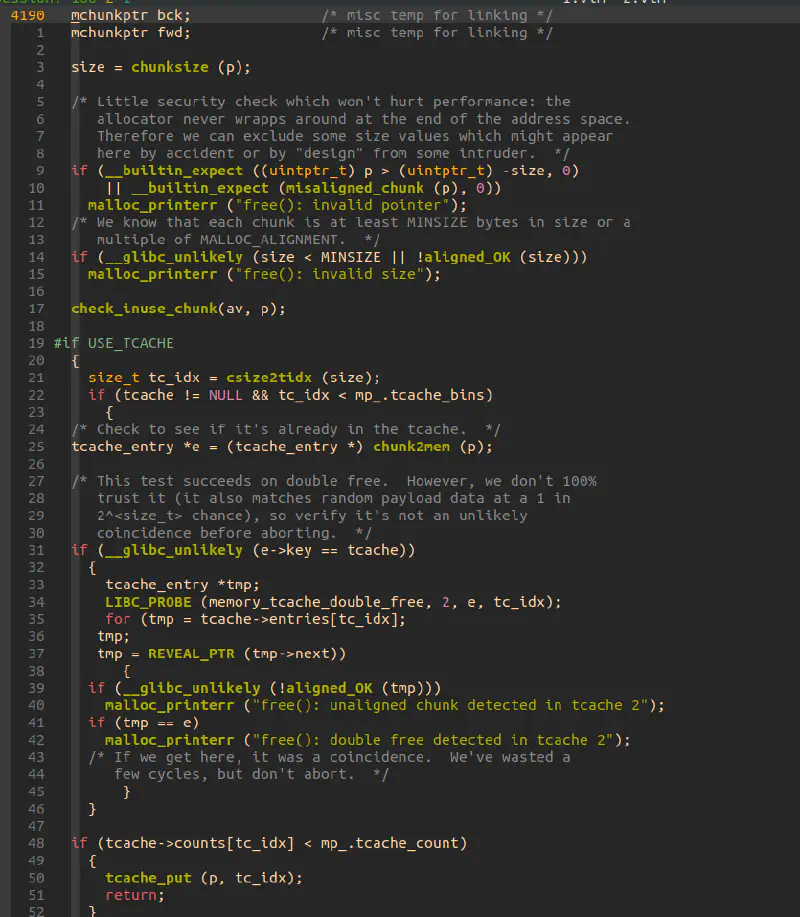
変更点は、e->key==tcacheだった場合の全探索においてリストを辿る際の for ループにおいて
REVEAL_PTRを使っていることくらいである。
これは、PROTECT_PTRによって加工した値からもとのアドレスを取り出す操作である。
_int_malloc()の変更点はこんな感じ:
fastbin 関係においても tcache と同様にREVEAL_PTRが使用されていることが分かる。
但し今回は tcache について見たいためtcache_get()の実装を以下に示す:
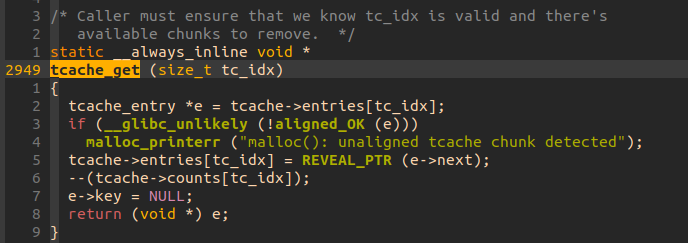
aligned_OK(e)というマクロを呼び、
チェックに失敗すると先程まさに現れたエラーメッセージが表示されるようになっている。
それでは aligned_OK は(名前から推測こそできるものの)何をしているかというと以下のようになっている:
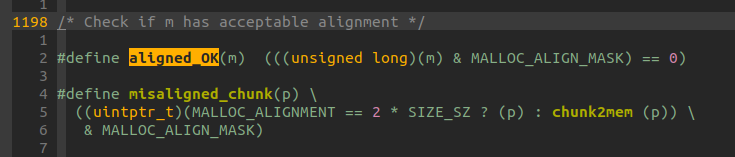
単純に与えられたポインタとMALLOC_ALIGN_MASK(==15)の論理積がゼロかを判断している。
これは、与えられたアドレスpが0x10 align されているかどうかを判断しているに他ならない。
さてここまでで大凡の仕組みは推測できるだろうが、以下で設計者の言葉も借りながら仕組みを総まとめする。
仕組み
Safe-Linking は単方向リストのポインタを加工することで、先にあげたようなポインタの書き換えによる攻撃を回避しようとする。
この加工は、_int_free()時にPROTECT_PTRマクロによって行われる。
このマクロがその chunk のアドレスと本来next(fd)に書き込むはずの値の xor を生成することは、先に見たとおりである。
先程の例を再掲する:
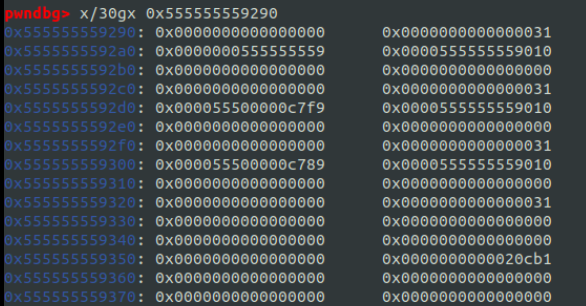
上から順に chunk A,B,C,D とし、ABC はこの順に free されて tcache に入っている。
例えば A まで free し、次に B を free する際のことを考えてみる。
このとき、従来ならばB(0x5555555592d0)のfdには A のアドレスである0x5555555592a0が入るはずである。
しかし今回の修正により、PROTECT_PTR(0x5555555592d0, 0x5555555592a0)が呼ばれることになった。
この内部では、((((size_t) pos) >> 12) ^ ((size_t) ptr)))という式すなわち0x5555555592d0>>12 ^ 0x5555555592a0によって、0x55500000c7f9という値が生成される:
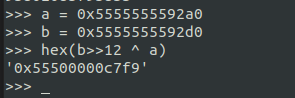
これはまさしく B のnextに入っている値と同一である。
それでは tcache のリンクを参照する際、すなわち tcache に複数の chunk が繋がった状態でmalloc()を呼び、
tcache に対して次の chunk のアドレスを書き込みたいという場合にはどうしているのだろうか。
つい先程見たように、C をmalloc()で取り出した後 B のnextにはPROTECT_PTRによって加工された値が入っているため、
tcache に直接書き込むわけには行かない
(そうしてしまうと、最早もとのアドレスを復元することは不可能になってしまう、復号に必要なのは加工された値とそのアドレスの 2 点なのだから)。
そこで、tcache_get()で見たようにREVEAL_PTRマクロによってもとの next の値を復元している。
PROTECT_PTRでは所詮 2 つの値を xor していただけだったから、復号も xor を行うだけで可能である
(そして実際にREVEAL_PTRの内部ではPROTECT_PTRを呼んでいる)。
そのようにして復元した値を tcache に書き込むのである。
ここで最も重要なのは、**「攻撃者は『攻撃の初期の段階においては』heap のアドレスを知らない」**という事実である。
これは、言わずもがな ASLR 有効の場合にはアドレス空間は下位 3nibble を除いてランダマイズされるからである。
先程PROTECT_PTRでわざわざ chunk のアドレスを 12bit 分シフトさせていたのは、
固定値の 3nibble ではなくランダマイズされたアドレス部を用いるためであった。
この事実と、「もとのnextを復元するためには加工をした結果の値とその chunk の heap 上の値が必要である」
という 2 つの事実を組み合わせることで、「攻撃者は初期の段階でもとの next の値を知ることができない」という結論が導かれる。
それでは、nextのもとの値のを知ることができないという事実を用いて如何にして linear overflow を検知するのかというと、ここで登場するのが先程のaligned_OKマクロである。
このマクロはREVEALED_PTRによって復元したnextの値が 0x10 align されているかどうかを確認する。
よって、linear overflow 等で next を書き換える際に、下 1nibble 分を適切に書き換えてやらないと、
このaligned_OKマクロで殺されることになる。
そう、おそらく気づいたと思うが、
このmitigation は 15/16 の確率でしか攻撃を検知できない。
overwrite した 1nibble がたまたま正確な値だった場合、エラーを検知できず書き換えられた値をもとにしてREVEAL_PTRされたアドレスをnextとして認識してしまうことになるのだ。
これが本エントリの冒頭で exploit を防ぐものではなく、失敗する確率を上げるものであると言った理由である。
設計者の言葉を借りるなら、raise the barらしい
というわけで、Safe-Linking の実装と仕組みを概観してきた。
上では tcache について見てきたが、この実装は一般の単方向リストに適用できるものであり、fastbin にも Safe-Linking が適用されている。
単純な tcache dup、とりわけよく知られた0x7Fテク等はこれで難しくなる。
尚、この実装は ASLR の生成する 3nibble 分のエントロピを利用したものであり、新たに実装されたコードは非常に少なくオーバーヘッドが小さい。 Ref よりベンチマーク試験の結果を以下に示す:
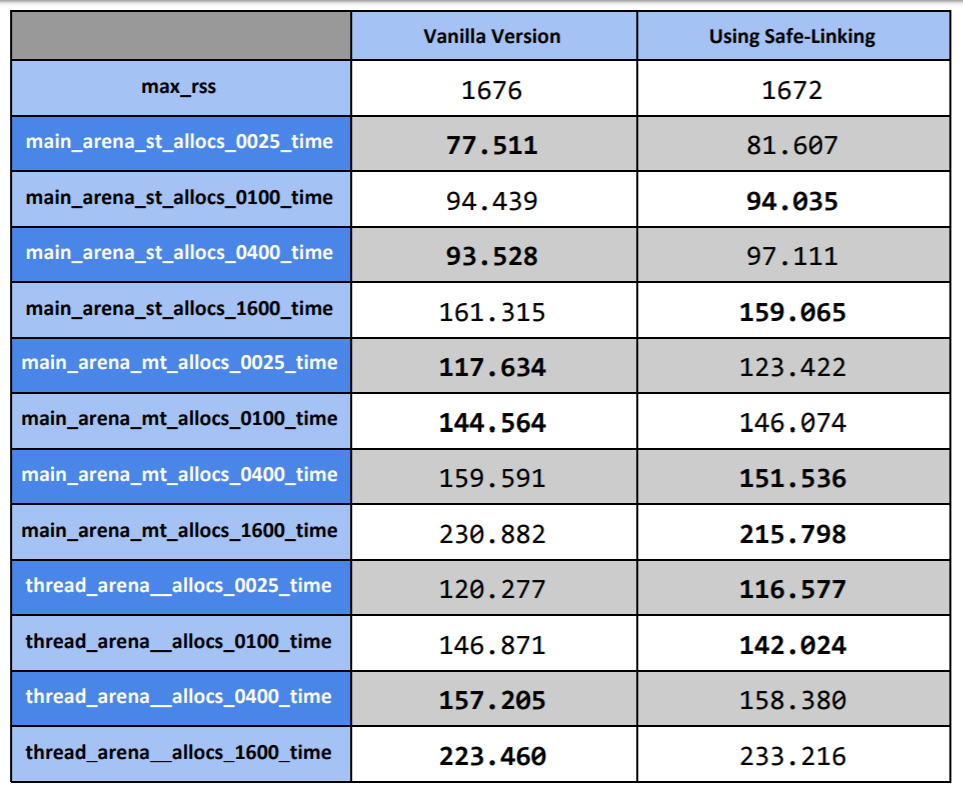
左が従来の malloc の実装、右が Safe-Linking を実装したものであるが、その殆どで差異がないことがわかる。 寧ろ Safe-Linking を実装したもののほうが高速に動作している項目も多いが、これは環境誤差であると考えられる。 すなわち誤差が大きく影響するほどには Safe-Linking 実装によるオーバーヘッドは小さいということが見て取れる。
House of io
Safe-Linking の Bypass について、まずはHouse of ioについて触れておく。
なんか突然Twitter で記事が流れてきた
為読んでみた。
Safe-Linking ではnext/fdを不正に書き換えたまま 2 回malloc()を行うとエラーが出るのは上に見たとおりである。
そこで、この bypass 方法では tcache のkeyを leak した上で、
tcache に直接書き換えたいアドレスを書き込んでいる。tcache に書き込まれるアドレス自体はPROTECT_PTRされていないため、もしこれができれば tcache_dup することができる。
但し、事前にkeyの leak が必要なことに加えて、何より AAW できないといけないことが、
現実/CTF の問題においてはかなり厳しく、そもそも AAW が可能であるならばもっと他に色々とできそうな気がしていて、
有効な手法なのかどうかは今の段階では疑わしい気がしている。
ということで、この手法について触れるのはここまでとする。
(追記: 2020.07.19)
@Awarau1 がHouse of ioについてのブログの Remaster 版 を公開したと教えてくれた。 今はまだ確認できていないが、あとで確認する。もしかしたら自分の解釈が間違っていて、凄く有効な方法なのかもしれない。
P'からLの leak
以下に、PROTECT_PTRの仕組みの外観図を参考記事
より拝借して提示する:
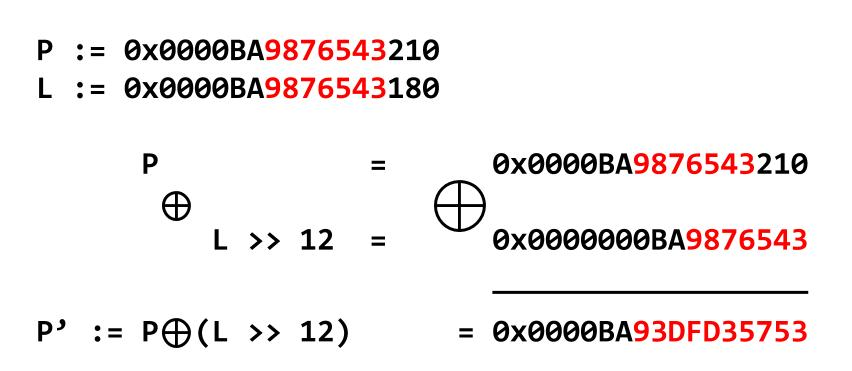
ここでPは tcache のnextに書き込まれるはずの本来のアドレス、LはPROTECT_PTRで加工に利用する chunk 自体のアドレス、
P'はLとPからPROTECT_PTRによって生成される値である。
ここで、free したあとの tcache にたいして 8byte のみ read が可能であるという状況を想定し、
「P'からLを復元したい」とする。以下に先程の例を再掲する:
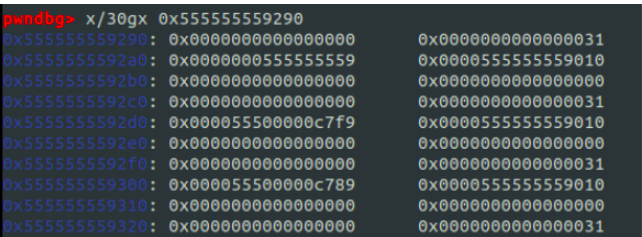
まず、全ての chunk に対して UAF(read)が可能であるならば、
Lの値は単に tcache の先端の chunk のnextを読むだけである。
上の例においては A を最初に free しているため tcache の先頭に繋がっているが、
A のnextにはLがそのまま格納されていることが見て取れる。
次に、B のP'のみが read できたとする。
このとき、Lは heap のアドレスを 12bit シフトしているため、
Pと比較して上位 3nibble が全て0になっている。
すなわち、P'の上位 3nibble はそのままLの値であることがわかる。
更に、Pの続く 2nibble は今 leak した L の上位 2nibble と xor しているため、
これも直ちに計算によって求めることができる。
この作業を繰り返すことによって、Pのみの情報からLを leak することが可能である。
Lを leak することができたということは(狭い文脈においては)heap のアドレスを完全に掌握できたことになるため、
あとは通常通りの overwrite をPROTECT_PTR 同じ計算を施してから行えば tcache dup が可能ということになる。
(勿論keyは適宜書き換える必要があるが、これは 1byte でも書き換えれば可能である。)
このように、対象 chunk が同一ページ内に配置され、且つその中でのオフセットが既知/操作でき、
8(or6)byte の leak が可能な場合においては、
従来と全く変わらずに tcache dup が可能になる。(但し全く read ができない状況においてnextの下 1byte だけを書き換えて循環 tcache を作るといったことは難しい)
上の画像で B のP'=0x000055500000C7F9のみからL=0x555555559が復元できることを以下のスクリプトで確かめられる:
1Pd = int(raw_input("P': "),16)
2L = Pd >> 36
3for i in range(3):
4 temp = (Pd >> (36-(i+1)*8)) & 0xff
5 element = ((L>>4) ^ temp) & 0xff
6 L = (L<<8) + element
7print("L : "+hex(L))

Further Attack
参考記事
に、
1byte の overflow でP'を leak し、Lを計算して任意の値を再び加工して overwrite する PoC が置いてある。
やっていることは、普通に consolidation を使って overlapping chunk を作り、生じた UAF でP'を leak するだけなので、特に目新しいことはしていないようである。
House of ioでもそうだったが、今のところはP'を leak することで通常通り overwrite をするという方法が一般的らしい。
アウトロ
設計者は 36C3 CTF をやっている最中にコレを思いついたらしいです。 俺が OnetimePad をなんとか殺している間に、設計者は pwner を殺そうとしていたのか…。 今回潰された/難しくされた脆弱性もそうですが、Intel CET が秋に出るとかどうとかという噂もあって、なんやかんや長い間放置されてきた脆弱性が消えていくのは、悲しいね。 因みにこの話を TSG slack でしたところ、物理こそ最強であり、爆破こそ至高という結論に至りました。 怖い人たちですね、僕は違いますが。 まぁ結局はどんどん新しい exploit が見つけられ、過去の exploit 達は忘れられていくのでしょう。 pwner 達は血も涙もない薄情糞野郎ばかりですから。